使用 SQLModel 创建表 - 使用 Engine¶
现在让我们开始编写代码。 👩💻
确保您位于项目目录中,并且您的虚拟环境已激活,如上一章所述。
我们将
- 使用 SQLModel 定义一个表
- 使用 SQLModel 创建相同的 SQLite 数据库和表
- 使用 DB Browser for SQLite 确认操作
这是我们想要的表结构的提醒
| id | name | secret_name | age |
|---|---|---|---|
| 1 | Deadpond | Dive Wilson | null |
| 2 | Spider-Boy | Pedro Parqueador | null |
| 3 | Rusty-Man | Tommy Sharp | 48 |
创建表模型类¶
我们首先需要做的是创建一个类来表示表中的数据。
像这样表示某些数据的类通常称为模型。
提示
这就是这个包被称为 SQLModel 的原因。因为它主要用于创建 SQL 模型。
为此,我们将导入 SQLModel(以及我们将要使用的其他内容),并创建一个继承自 SQLModel 并表示我们的英雄的表模型的类 Hero
from sqlmodel import Field, SQLModel, create_engine
class Hero(SQLModel, table=True):
id: int | None = Field(default=None, primary_key=True)
name: str
secret_name: str
age: int | None = None
# Code below omitted 👇
👀 完整文件预览
from sqlmodel import Field, SQLModel, create_engine
class Hero(SQLModel, table=True):
id: int | None = Field(default=None, primary_key=True)
name: str
secret_name: str
age: int | None = None
sqlite_file_name = "database.db"
sqlite_url = f"sqlite:///{sqlite_file_name}"
engine = create_engine(sqlite_url, echo=True)
SQLModel.metadata.create_all(engine)
🤓 其他版本和变体
from typing import Optional
from sqlmodel import Field, SQLModel, create_engine
class Hero(SQLModel, table=True):
id: Optional[int] = Field(default=None, primary_key=True)
name: str
secret_name: str
age: Optional[int] = None
sqlite_file_name = "database.db"
sqlite_url = f"sqlite:///{sqlite_file_name}"
engine = create_engine(sqlite_url, echo=True)
SQLModel.metadata.create_all(engine)
这个类 Hero 表示我们的英雄的表。我们稍后创建的每个实例将表示表中的一行。
我们使用配置 table=True 来告诉 SQLModel 这是一个表模型,它表示一个表。
信息
也可以拥有没有 table=True 的模型,这些模型将仅是数据模型,在数据库中没有表,它们将不是表模型。
这些数据模型将在稍后非常有用,但现在,我们只保留添加 table=True 配置。
定义字段、列¶
下一步是通过使用标准 Python 类型注解来定义类的字段或列。
这些变量中的每一个的名称将是表中的列的名称。
它们的类型也将是表列的类型
from sqlmodel import Field, SQLModel, create_engine
class Hero(SQLModel, table=True):
id: int | None = Field(default=None, primary_key=True)
name: str
secret_name: str
age: int | None = None
# Code below omitted 👇
👀 完整文件预览
from sqlmodel import Field, SQLModel, create_engine
class Hero(SQLModel, table=True):
id: int | None = Field(default=None, primary_key=True)
name: str
secret_name: str
age: int | None = None
sqlite_file_name = "database.db"
sqlite_url = f"sqlite:///{sqlite_file_name}"
engine = create_engine(sqlite_url, echo=True)
SQLModel.metadata.create_all(engine)
🤓 其他版本和变体
from typing import Optional
from sqlmodel import Field, SQLModel, create_engine
class Hero(SQLModel, table=True):
id: Optional[int] = Field(default=None, primary_key=True)
name: str
secret_name: str
age: Optional[int] = None
sqlite_file_name = "database.db"
sqlite_url = f"sqlite:///{sqlite_file_name}"
engine = create_engine(sqlite_url, echo=True)
SQLModel.metadata.create_all(engine)
现在让我们更详细地了解这些字段/列声明。
可选字段、可为空列¶
让我们从 age 开始,请注意它的类型为 int | None (或 Optional[int])。
我们从 typing 标准模块导入 Optional。
这是在 Python 中声明某事物“可以是 int 或 None”的标准方法。
我们还将 age 的默认值设置为 None。
from sqlmodel import Field, SQLModel, create_engine
class Hero(SQLModel, table=True):
id: int | None = Field(default=None, primary_key=True)
name: str
secret_name: str
age: int | None = None
# Code below omitted 👇
👀 完整文件预览
from sqlmodel import Field, SQLModel, create_engine
class Hero(SQLModel, table=True):
id: int | None = Field(default=None, primary_key=True)
name: str
secret_name: str
age: int | None = None
sqlite_file_name = "database.db"
sqlite_url = f"sqlite:///{sqlite_file_name}"
engine = create_engine(sqlite_url, echo=True)
SQLModel.metadata.create_all(engine)
🤓 其他版本和变体
from typing import Optional
from sqlmodel import Field, SQLModel, create_engine
class Hero(SQLModel, table=True):
id: Optional[int] = Field(default=None, primary_key=True)
name: str
secret_name: str
age: Optional[int] = None
sqlite_file_name = "database.db"
sqlite_url = f"sqlite:///{sqlite_file_name}"
engine = create_engine(sqlite_url, echo=True)
SQLModel.metadata.create_all(engine)
提示
我们还使用 Optional 定义了 id。但我们将在下面讨论 id。
这样,我们告诉 SQLModel,age 在验证数据时不是必需的,并且它具有默认值 None。
我们还告诉它,在 SQL 数据库中,age 的默认值为 NULL(SQL 中等同于 Python 的 None)。
因此,此列是“可为空的”(可以设置为 NULL)。
信息
在 Pydantic 方面,age 是一个可选字段。
在 SQLAlchemy 方面,age 是一个可为空列。
主键 id¶
现在让我们回顾一下 id 字段。这是表的主键。
因此,我们需要将 id 标记为主键。
为此,我们使用来自 sqlmodel 的特殊 Field 函数,并将参数 primary_key=True 设置为
from sqlmodel import Field, SQLModel, create_engine
class Hero(SQLModel, table=True):
id: int | None = Field(default=None, primary_key=True)
name: str
secret_name: str
age: int | None = None
# Code below omitted 👇
👀 完整文件预览
from sqlmodel import Field, SQLModel, create_engine
class Hero(SQLModel, table=True):
id: int | None = Field(default=None, primary_key=True)
name: str
secret_name: str
age: int | None = None
sqlite_file_name = "database.db"
sqlite_url = f"sqlite:///{sqlite_file_name}"
engine = create_engine(sqlite_url, echo=True)
SQLModel.metadata.create_all(engine)
🤓 其他版本和变体
from typing import Optional
from sqlmodel import Field, SQLModel, create_engine
class Hero(SQLModel, table=True):
id: Optional[int] = Field(default=None, primary_key=True)
name: str
secret_name: str
age: Optional[int] = None
sqlite_file_name = "database.db"
sqlite_url = f"sqlite:///{sqlite_file_name}"
engine = create_engine(sqlite_url, echo=True)
SQLModel.metadata.create_all(engine)
这样,我们告诉 SQLModel,此 id 字段/列是表的主键。
但是在 SQL 数据库中,它是始终必需的,并且不能为 NULL。我们为什么要用 Optional 声明它呢?
id 在数据库中是必需的,但它将由数据库生成,而不是由我们的代码生成。
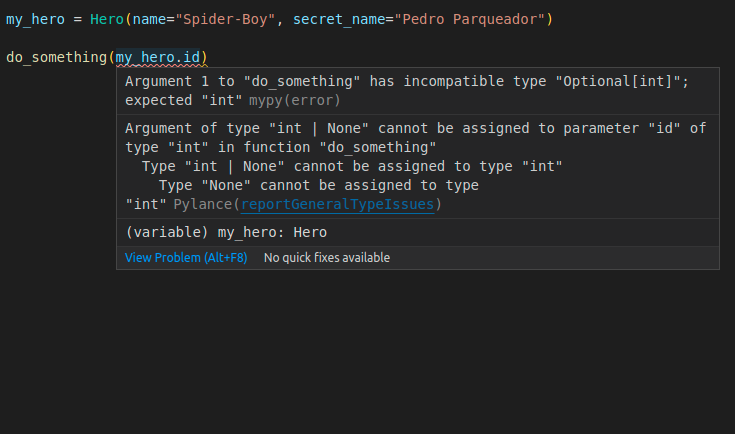
因此,每当我们创建此类的实例(在接下来的章节中)时,我们不会设置 id。 并且 id 的值将为 None直到我们将其保存在数据库中,然后它最终将具有一个值。
my_hero = Hero(name="Spider-Boy", secret_name="Pedro Parqueador")
do_something(my_hero.id) # Oh no! my_hero.id is None! 😱🚨
# Imagine this saves it to the database
somehow_save_in_db(my_hero)
do_something(my_hero.id) # Now my_hero.id has a value generated in DB 🎉
因此,因为在我们的代码中(而不是在数据库中),id 的值可能为 None,所以我们使用 Optional。 这样,编辑器将能够帮助我们,例如,如果我们尝试访问我们尚未保存在数据库中的对象的 id,并且该 id 仍然是 None。
现在,因为我们正在使用我们的 Field() 函数替换默认值,所以我们在 Field() 中使用参数 default=None 将 id 的实际默认值设置为 None
Field(default=None)
如果我们没有设置 default 值,那么每当我们稍后使用此模型进行数据验证(由 Pydantic 提供支持)时,它将接受除 int 之外的 None 值,但它仍然会要求传递该 None 值。 并且对于以后使用此模型的人(可能就是我们)来说会感到困惑,所以最好在此处设置默认值。
创建 Engine¶
现在我们需要创建 SQLAlchemy Engine。
它是一个处理与数据库通信的对象。
如果您有服务器数据库(例如 PostgreSQL 或 MySQL),则 engine 将保存到该数据库的网络连接。
创建 engine 非常简单,只需使用要使用的数据库的 URL 调用 create_engine() 即可
from sqlmodel import Field, SQLModel, create_engine
class Hero(SQLModel, table=True):
id: int | None = Field(default=None, primary_key=True)
name: str
secret_name: str
age: int | None = None
sqlite_file_name = "database.db"
sqlite_url = f"sqlite:///{sqlite_file_name}"
engine = create_engine(sqlite_url, echo=True)
SQLModel.metadata.create_all(engine)
👀 完整文件预览
from sqlmodel import Field, SQLModel, create_engine
class Hero(SQLModel, table=True):
id: int | None = Field(default=None, primary_key=True)
name: str
secret_name: str
age: int | None = None
sqlite_file_name = "database.db"
sqlite_url = f"sqlite:///{sqlite_file_name}"
engine = create_engine(sqlite_url, echo=True)
SQLModel.metadata.create_all(engine)
🤓 其他版本和变体
from typing import Optional
from sqlmodel import Field, SQLModel, create_engine
class Hero(SQLModel, table=True):
id: Optional[int] = Field(default=None, primary_key=True)
name: str
secret_name: str
age: Optional[int] = None
sqlite_file_name = "database.db"
sqlite_url = f"sqlite:///{sqlite_file_name}"
engine = create_engine(sqlite_url, echo=True)
SQLModel.metadata.create_all(engine)
通常,您应该为整个应用程序拥有一个 engine 对象,并在所有地方重复使用它。
提示
还有另一个相关的东西叫做 Session,通常不应该是每个应用程序的单个对象。
但我们稍后会讨论它。
Engine 数据库 URL¶
每个支持的数据库都有自己的 URL 类型。 例如,对于 SQLite,它是 sqlite:///,后跟文件路径。 例如
sqlite:///database.dbsqlite:///databases/local/application.dbsqlite:///db.sqlite
SQLite 支持一个特殊的数据库,该数据库完全存在于内存中。 因此,它非常快,但请注意,数据库会在程序终止后被删除。 您可以通过仅使用两个斜杠字符(//)且不带文件名来指定此内存数据库
sqlite://
from sqlmodel import Field, SQLModel, create_engine
class Hero(SQLModel, table=True):
id: int | None = Field(default=None, primary_key=True)
name: str
secret_name: str
age: int | None = None
sqlite_file_name = "database.db"
sqlite_url = f"sqlite:///{sqlite_file_name}"
engine = create_engine(sqlite_url, echo=True)
SQLModel.metadata.create_all(engine)
👀 完整文件预览
from sqlmodel import Field, SQLModel, create_engine
class Hero(SQLModel, table=True):
id: int | None = Field(default=None, primary_key=True)
name: str
secret_name: str
age: int | None = None
sqlite_file_name = "database.db"
sqlite_url = f"sqlite:///{sqlite_file_name}"
engine = create_engine(sqlite_url, echo=True)
SQLModel.metadata.create_all(engine)
🤓 其他版本和变体
from typing import Optional
from sqlmodel import Field, SQLModel, create_engine
class Hero(SQLModel, table=True):
id: Optional[int] = Field(default=None, primary_key=True)
name: str
secret_name: str
age: Optional[int] = None
sqlite_file_name = "database.db"
sqlite_url = f"sqlite:///{sqlite_file_name}"
engine = create_engine(sqlite_url, echo=True)
SQLModel.metadata.create_all(engine)
您可以在 SQLAlchemy 文档中阅读更多关于 SQLAlchemy 支持的所有数据库(以及 SQLModel 支持的数据库)的信息。
Engine 回显¶
在此示例中,我们还使用了参数 echo=True。
它将使 engine 打印它执行的所有 SQL 语句,这可以帮助您了解发生了什么。
它对于学习和调试尤其有用
from sqlmodel import Field, SQLModel, create_engine
class Hero(SQLModel, table=True):
id: int | None = Field(default=None, primary_key=True)
name: str
secret_name: str
age: int | None = None
sqlite_file_name = "database.db"
sqlite_url = f"sqlite:///{sqlite_file_name}"
engine = create_engine(sqlite_url, echo=True)
SQLModel.metadata.create_all(engine)
👀 完整文件预览
from sqlmodel import Field, SQLModel, create_engine
class Hero(SQLModel, table=True):
id: int | None = Field(default=None, primary_key=True)
name: str
secret_name: str
age: int | None = None
sqlite_file_name = "database.db"
sqlite_url = f"sqlite:///{sqlite_file_name}"
engine = create_engine(sqlite_url, echo=True)
SQLModel.metadata.create_all(engine)
🤓 其他版本和变体
from typing import Optional
from sqlmodel import Field, SQLModel, create_engine
class Hero(SQLModel, table=True):
id: Optional[int] = Field(default=None, primary_key=True)
name: str
secret_name: str
age: Optional[int] = None
sqlite_file_name = "database.db"
sqlite_url = f"sqlite:///{sqlite_file_name}"
engine = create_engine(sqlite_url, echo=True)
SQLModel.metadata.create_all(engine)
但在生产环境中,您可能需要删除 echo=True
engine = create_engine(sqlite_url)
Engine 技术细节¶
提示
如果您以前不了解 SQLAlchemy 并且只是在学习 SQLModel,则可以跳过本节,向下滚动。
您可以在 SQLAlchemy 文档中阅读更多关于 engine 的信息。
SQLModel 定义了自己的 create_engine() 函数。 它与 SQLAlchemy 的 create_engine() 相同,但不同之处在于它默认使用 future=True(这意味着它使用最新的 SQLAlchemy 1.4 和未来的 2.0 的样式)。
并且 SQLModel 版本的 create_engine() 在内部进行了类型注解,因此您的编辑器将能够通过自动完成和内联错误来帮助您。
创建数据库和表¶
现在一切就绪,最终可以创建数据库和表了
from sqlmodel import Field, SQLModel, create_engine
class Hero(SQLModel, table=True):
id: int | None = Field(default=None, primary_key=True)
name: str
secret_name: str
age: int | None = None
sqlite_file_name = "database.db"
sqlite_url = f"sqlite:///{sqlite_file_name}"
engine = create_engine(sqlite_url, echo=True)
SQLModel.metadata.create_all(engine)
🤓 其他版本和变体
from typing import Optional
from sqlmodel import Field, SQLModel, create_engine
class Hero(SQLModel, table=True):
id: Optional[int] = Field(default=None, primary_key=True)
name: str
secret_name: str
age: Optional[int] = None
sqlite_file_name = "database.db"
sqlite_url = f"sqlite:///{sqlite_file_name}"
engine = create_engine(sqlite_url, echo=True)
SQLModel.metadata.create_all(engine)
提示
创建 engine 不会创建 database.db 文件。
但是一旦我们运行 SQLModel.metadata.create_all(engine),它就会创建 database.db 文件并在该数据库中创建 hero 表。
这两件事都在这一个步骤中完成。
让我们解开它
SQLModel.metadata.create_all(engine)
SQLModel MetaData¶
SQLModel 类具有 metadata 属性。 它是 MetaData 类的实例。
每当您创建一个继承自 SQLModel 并配置了 table = True 的类时,它都会在此 metadata 属性中注册。
因此,到最后一行,SQLModel.metadata 已经注册了 Hero。
调用 create_all()¶
SQLModel.metadata 处的此 MetaData 对象具有 create_all() 方法。
它接受一个 engine 并使用它来创建数据库和在此 MetaData 对象中注册的所有表。
SQLModel MetaData 顺序很重要¶
这也意味着您必须在创建从 SQLModel 继承的新模型类的代码之后调用 SQLModel.metadata.create_all()。
例如,让我们想象一下您这样做
- 在一个 Python 文件
models.py中创建模型。 - 在文件
db.py中创建 engine 对象。 - 在
app.py中创建您的主应用程序并调用SQLModel.metadata.create_all()。
如果您仅导入 SQLModel 并尝试在 app.py 中调用 SQLModel.metadata.create_all(),则它不会创建您的表
# This wouldn't work! 🚨
from sqlmodel import SQLModel
from .db import engine
SQLModel.metadata.create_all(engine)
它将不起作用,因为当您单独导入 SQLModel 时,Python 不会执行创建从它继承的类的所有代码(在我们的示例中,类 Hero),因此 SQLModel.metadata 仍然为空。
但是,如果您在调用 SQLModel.metadata.create_all()之前导入模型,它将起作用
from sqlmodel import SQLModel
from . import models
from .db import engine
SQLModel.metadata.create_all(engine)
这将起作用,因为通过导入模型,Python 会执行创建从 SQLModel 继承的类并将它们注册到 SQLModel.metadata 中的所有代码。
作为替代方案,您可以在 db.py 内部导入 SQLModel 和您的模型
# db.py
from sqlmodel import SQLModel, create_engine
from . import models
sqlite_file_name = "database.db"
sqlite_url = f"sqlite:///{sqlite_file_name}"
engine = create_engine(sqlite_url)
然后在 app.py 中从 db.py 导入 SQLModel,并在那里调用 SQLModel.metadata.create_all()
# app.py
from .db import engine, SQLModel
SQLModel.metadata.create_all(engine)
从 db.py 导入 SQLModel 将起作用,因为 SQLModel 也已在 db.py 中导入。
并且这个技巧将正确工作并在数据库中创建表,因为通过从 db.py 导入 SQLModel,Python 会执行在该 db.py 文件中创建从 SQLModel 继承的类的所有代码,例如,类 Hero。
迁移¶
对于这个简单的示例,以及对于大多数教程 - 用户指南,使用 SQLModel.metadata.create_all() 就足够了。
但是对于生产系统,您可能需要使用系统来迁移数据库。
例如,当您添加或删除列、添加新表、更改类型等时,这将非常有用和重要。
但是您将在高级用户指南中了解有关迁移的更多信息。
运行程序¶
让我们运行程序以查看其全部工作。
如果您尚未这样做,请将代码放在文件 app.py 中。
from sqlmodel import Field, SQLModel, create_engine
class Hero(SQLModel, table=True):
id: int | None = Field(default=None, primary_key=True)
name: str
secret_name: str
age: int | None = None
sqlite_file_name = "database.db"
sqlite_url = f"sqlite:///{sqlite_file_name}"
engine = create_engine(sqlite_url, echo=True)
SQLModel.metadata.create_all(engine)
🤓 其他版本和变体
from typing import Optional
from sqlmodel import Field, SQLModel, create_engine
class Hero(SQLModel, table=True):
id: Optional[int] = Field(default=None, primary_key=True)
name: str
secret_name: str
age: Optional[int] = None
sqlite_file_name = "database.db"
sqlite_url = f"sqlite:///{sqlite_file_name}"
engine = create_engine(sqlite_url, echo=True)
SQLModel.metadata.create_all(engine)
提示
请记住在运行它之前激活虚拟环境。
现在使用 Python 运行程序
// We set echo=True, so this will show the SQL code
$ python app.py
// First, some boilerplate SQL that we are not that interested in
INFO Engine BEGIN (implicit)
INFO Engine PRAGMA main.table_info("hero")
INFO Engine [raw sql] ()
INFO Engine PRAGMA temp.table_info("hero")
INFO Engine [raw sql] ()
INFO Engine
// Finally, the glorious SQL to create the table ✨
CREATE TABLE hero (
id INTEGER,
name VARCHAR NOT NULL,
secret_name VARCHAR NOT NULL,
age INTEGER,
PRIMARY KEY (id)
)
// More SQL boilerplate
INFO Engine [no key 0.00020s] ()
INFO Engine COMMIT
信息
我简化了上面的输出,使其更易于阅读。
但实际上,而不是显示
INFO Engine BEGIN (implicit)
它会显示类似
2021-07-25 21:37:39,175 INFO sqlalchemy.engine.Engine BEGIN (implicit)
TEXT 或 VARCHAR¶
在上一章的示例中,我们对某些列使用 TEXT 创建了表。
但是在此输出中,SQLAlchemy 正在使用 VARCHAR 代替。 让我们看看发生了什么。
还记得每个 SQL 数据库在它们支持的内容上都有一些不同的变体吗?
这是一个差异。 每个数据库都支持一些特定的数据类型,例如 INTEGER 和 TEXT。
某些数据库具有一些用于特定事物的特定类型。 例如,PostgreSQL 和 MySQL 支持 BOOLEAN 用于 True 和 False 值。 SQLite 接受带有布尔值的 SQL,即使在定义表列时也是如此,但它在内部实际使用的是 INTEGER,其中 1 表示 True,0 表示 False。
同样,有几种可能的类型用于存储字符串。 SQLite 使用 TEXT 类型。 但是其他数据库(如 PostgreSQL 和 MySQL)默认使用 VARCHAR 类型,而 VARCHAR 是最常见的数据类型之一。
VARCHAR 来自可变长度字符。
SQLAlchemy 生成 SQL 语句以使用 VARCHAR 创建表,然后 SQLite 接收它们,并在内部将它们转换为 TEXT。
除了这两种数据类型之间的差异之外,某些数据库(如 MySQL)还要求为 VARCHAR 类型设置最大长度,例如 VARCHAR(255) 将最大字符数设置为 255。
为了更容易地开始使用 SQLModel,而无需考虑您使用的数据库(即使是 MySQL),并且无需任何额外的配置,默认情况下,str 字段在大多数数据库中被解释为 VARCHAR,在 MySQL 中被解释为 VARCHAR(255),这样您就知道同一个类将与最流行的数据库兼容,而无需额外的努力。
提示
您将在高级教程 - 用户指南中学习如何更改字符串列的最大长度。
验证数据库¶
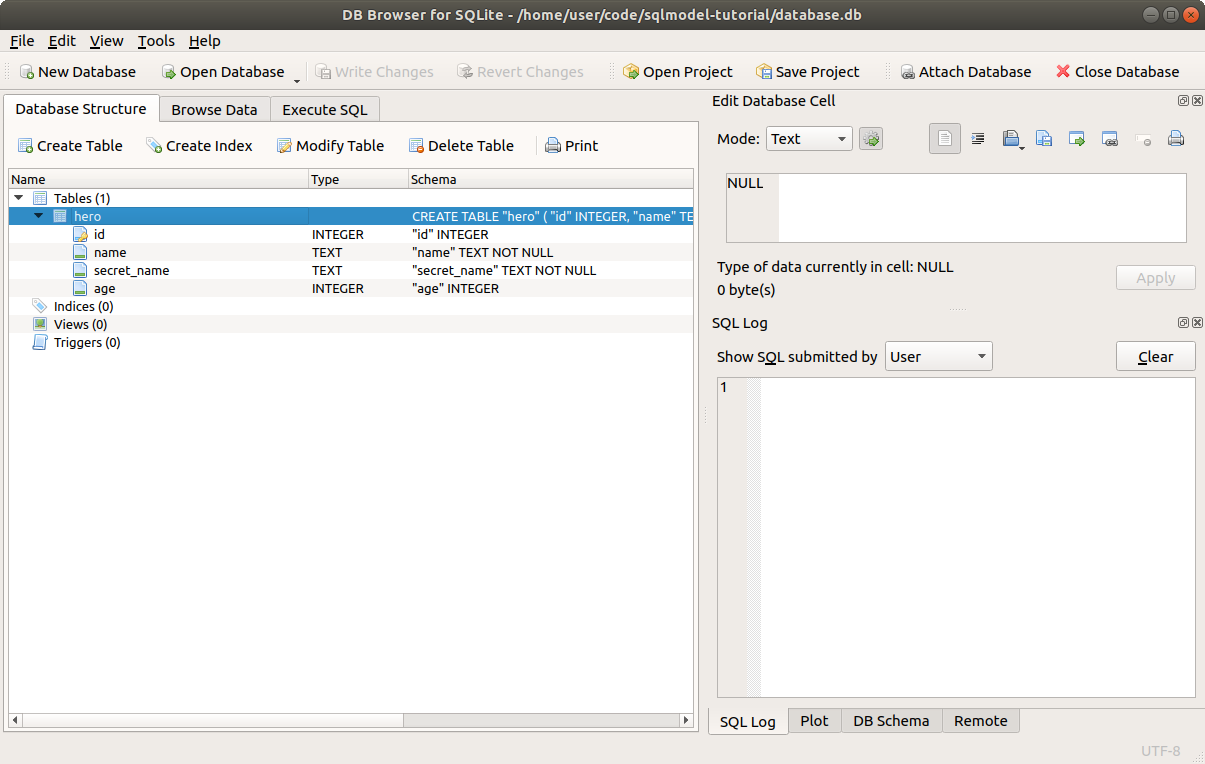
现在,使用 DB Browser for SQLite 打开数据库,您将看到程序创建了表 hero,就像以前一样。 🎉
重构数据创建¶
现在让我们稍微重组代码,使其更易于重用、共享和测试。
让我们将具有主要副作用的代码(更改数据,创建包含数据库和表的文件)移动到一个函数中。
在此示例中,它只是 SQLModel.metadata.create_all(engine)。
让我们将其放入函数 create_db_and_tables() 中
from sqlmodel import Field, SQLModel, create_engine
class Hero(SQLModel, table=True):
id: int | None = Field(default=None, primary_key=True)
name: str
secret_name: str
age: int | None = None
sqlite_file_name = "database.db"
sqlite_url = f"sqlite:///{sqlite_file_name}"
engine = create_engine(sqlite_url, echo=True)
def create_db_and_tables():
SQLModel.metadata.create_all(engine)
# Code below omitted 👇
👀 完整文件预览
from sqlmodel import Field, SQLModel, create_engine
class Hero(SQLModel, table=True):
id: int | None = Field(default=None, primary_key=True)
name: str
secret_name: str
age: int | None = None
sqlite_file_name = "database.db"
sqlite_url = f"sqlite:///{sqlite_file_name}"
engine = create_engine(sqlite_url, echo=True)
def create_db_and_tables():
SQLModel.metadata.create_all(engine)
if __name__ == "__main__":
create_db_and_tables()
🤓 其他版本和变体
from typing import Optional
from sqlmodel import Field, SQLModel, create_engine
class Hero(SQLModel, table=True):
id: Optional[int] = Field(default=None, primary_key=True)
name: str
secret_name: str
age: Optional[int] = None
sqlite_file_name = "database.db"
sqlite_url = f"sqlite:///{sqlite_file_name}"
engine = create_engine(sqlite_url, echo=True)
def create_db_and_tables():
SQLModel.metadata.create_all(engine)
if __name__ == "__main__":
create_db_and_tables()
如果 SQLModel.metadata.create_all(engine) 不在函数中,并且我们尝试从另一个模块(从该文件)导入某些内容,则每次我们执行导入此模块的其他文件时,它都会尝试创建数据库和表。
我们不希望那样发生,仅当我们打算这样做时才发生,这就是为什么我们将其放入函数中的原因,因为我们可以确保仅在我们调用该函数时才创建表,而不是在此模块在其他地方导入时创建表。
现在,我们将能够例如在其他文件中导入 Hero 类,而不会产生这些副作用。
提示
😅 剧透警告:该函数被称为 create_db_and_tables(),因为将来除了 Hero 之外,我们还将有更多具有其他类的表。 🚀
将数据创建为脚本¶
我们阻止了从您的 app.py 文件导入某些内容时的副作用。
但是我们仍然希望在直接使用 Python 从终端调用它作为独立脚本时创建数据库和表,就像上面一样。
提示
将单词脚本和程序视为可互换的。
单词脚本通常意味着代码可以独立且轻松地运行。 或者在某些情况下,它指的是相对简单的程序。
为此,我们可以使用 if 块中的特殊变量 __name__
from sqlmodel import Field, SQLModel, create_engine
class Hero(SQLModel, table=True):
id: int | None = Field(default=None, primary_key=True)
name: str
secret_name: str
age: int | None = None
sqlite_file_name = "database.db"
sqlite_url = f"sqlite:///{sqlite_file_name}"
engine = create_engine(sqlite_url, echo=True)
def create_db_and_tables():
SQLModel.metadata.create_all(engine)
if __name__ == "__main__":
create_db_and_tables()
🤓 其他版本和变体
from typing import Optional
from sqlmodel import Field, SQLModel, create_engine
class Hero(SQLModel, table=True):
id: Optional[int] = Field(default=None, primary_key=True)
name: str
secret_name: str
age: Optional[int] = None
sqlite_file_name = "database.db"
sqlite_url = f"sqlite:///{sqlite_file_name}"
engine = create_engine(sqlite_url, echo=True)
def create_db_and_tables():
SQLModel.metadata.create_all(engine)
if __name__ == "__main__":
create_db_and_tables()
关于 __name__ == "__main__"¶
__name__ == "__main__" 的主要目的是拥有一些代码,当您的文件被调用时执行
$ python app.py
// Something happens here ✨
...但当另一个文件导入它时不会被调用,例如在
from app import Hero
更多细节¶
假设您的文件名为 myapp.py。
如果您使用以下命令运行它
$ python myapp.py
// This will call create_db_and_tables()
...那么由 Python 自动创建的文件中的内部变量 __name__ 的值将为字符串 "__main__"。
因此,在
if __name__ == "__main__":
create_db_and_tables()
...中的函数将运行。
如果您导入该模块(文件),则不会发生这种情况。
因此,如果您有另一个文件 importer.py,其中包含
from myapp import Hero
# Some more code
...在这种情况下,myapp.py 内部的自动变量将不会使变量 __name__ 的值为 "__main__"。
因此,行
if __name__ == "__main__":
create_db_and_tables()
...将不会被执行。
信息
有关更多信息,请查看 官方 Python 文档。
上次回顾¶
进行这些更改后,您可以再次运行它,它将生成与以前相同的输出。
但是现在我们可以在其他文件中从此模块导入内容。
现在,让我们最后看一下代码
from sqlmodel import Field, SQLModel, create_engine # (2)!
class Hero(SQLModel, table=True): # (3)!
id: int | None = Field(default=None, primary_key=True) # (4)!
name: str # (5)!
secret_name: str # (6)!
age: int | None = None # (7)!
sqlite_file_name = "database.db" # (8)!
sqlite_url = f"sqlite:///{sqlite_file_name}" # (9)!
engine = create_engine(sqlite_url, echo=True) # (10)!
def create_db_and_tables(): # (11)!
SQLModel.metadata.create_all(engine) # (12)!
if __name__ == "__main__": # (13)!
create_db_and_tables() # (14)!
- 从
typing导入Optional以声明可能为None的字段。 - 从
sqlmodel导入我们将需要的内容:Field、SQLModel、create_engine。 -
创建
Hero模型类,表示数据库中的hero表。并使用
table=True将此类也标记为表模型。 -
创建
id字段在数据库为其分配值之前,它可能为
None,因此我们使用Optional对其进行注解。它是一个主键,因此我们使用
Field()和参数primary_key=True。 -
创建
name字段。它是必需的,因此没有默认值,也不是
Optional。 -
创建
secret_name字段。也是必需的。
-
创建
age字段。不是必需的,默认值为
None。在数据库中,默认值将为
NULL,SQL 中等同于None。由于此字段可能为
None(以及数据库中的NULL),因此我们使用Optional对其进行注解。 -
写入数据库文件的名称。
- 使用数据库文件的名称来创建数据库 URL。
-
使用 URL 创建 engine。
这尚未创建数据库,此时尚未创建文件或表,仅创建 engine 对象,该对象将处理与此特定数据库的连接,以及对 SQLite 的特定支持(基于 URL)。
-
将创建副作用的代码放入函数中。
在这种情况下,只有一行代码创建带有表数据库文件。
-
创建所有自动注册到
SQLModel.metadata中的表。 -
添加主块或“顶层脚本环境”。
并放入一些逻辑以在直接使用 Python 调用时执行,如
$ python app.py // Execute all the stuff and show the output...但当从该模块导入某些内容时不会执行,例如
from app import Hero -
在此主块中,调用创建数据库文件和表的函数。
这样,当我们使用以下命令调用它时
$ python app.py // Doing stuff ✨...它将创建数据库文件和表。
from typing import Optional # (1)!
from sqlmodel import Field, SQLModel, create_engine # (2)!
class Hero(SQLModel, table=True): # (3)!
id: Optional[int] = Field(default=None, primary_key=True) # (4)!
name: str # (5)!
secret_name: str # (6)!
age: Optional[int] = None # (7)!
sqlite_file_name = "database.db" # (8)!
sqlite_url = f"sqlite:///{sqlite_file_name}" # (9)!
engine = create_engine(sqlite_url, echo=True) # (10)!
def create_db_and_tables(): # (11)!
SQLModel.metadata.create_all(engine) # (12)!
if __name__ == "__main__": # (13)!
create_db_and_tables() # (14)!
- 从
typing导入Optional以声明可能为None的字段。 - 从
sqlmodel导入我们将需要的内容:Field、SQLModel、create_engine。 -
创建
Hero模型类,表示数据库中的hero表。并使用
table=True将此类也标记为表模型。 -
创建
id字段在数据库为其分配值之前,它可能为
None,因此我们使用Optional对其进行注解。它是一个主键,因此我们使用
Field()和参数primary_key=True。 -
创建
name字段。它是必需的,因此没有默认值,也不是
Optional。 -
创建
secret_name字段。也是必需的。
-
创建
age字段。不是必需的,默认值为
None。在数据库中,默认值将为
NULL,SQL 中等同于None。由于此字段可能为
None(以及数据库中的NULL),因此我们使用Optional对其进行注解。 -
写入数据库文件的名称。
- 使用数据库文件的名称来创建数据库 URL。
-
使用 URL 创建 engine。
这尚未创建数据库,此时尚未创建文件或表,仅创建 engine 对象,该对象将处理与此特定数据库的连接,以及对 SQLite 的特定支持(基于 URL)。
-
将创建副作用的代码放入函数中。
在这种情况下,只有一行代码创建带有表数据库文件。
-
创建所有自动注册到
SQLModel.metadata中的表。 -
添加主块或“顶层脚本环境”。
并放入一些逻辑以在直接使用 Python 调用时执行,如
$ python app.py // Execute all the stuff and show the output...但当从该模块导入某些内容时不会执行,例如
from app import Hero -
在此主块中,调用创建数据库文件和表的函数。
这样,当我们使用以下命令调用它时
$ python app.py // Doing stuff ✨...它将创建数据库文件和表。
提示
通过单击代码中的每个数字气泡来查看每一行代码的作用。 👆
概括¶
我们学习了如何使用 SQLModel 定义数据库中表的应有外观,并且我们使用 SQLModel 创建了一个数据库和一个表。
我们还重构了代码,使其更易于重用、共享和稍后测试。
在接下来的章节中,我们将看到 SQLModel 如何帮助我们从代码与 SQL 数据库进行交互。 🤓